
- Blue Energy
-

- Blog
-
- Data Source Framework – czyli jak optymalnie dobrać źródła danych do monitorowania bezpieczeństwa
Data Source Framework – czyli jak optymalnie dobrać źródła danych do monitorowania bezpieczeństwa
 20 lip 2023
20 lip 2023  Jarosław Kuta
Jarosław Kuta Projektując architekturę systemów bezpieczeństwa, często spotykam problem nieoptymalnego doboru źródeł danych do systemów protekcji. Przykładem takiego stanu jest integracja do systemu SIEM jedynie warstwy systemu operacyjnego, zapominając o serwerze aplikacyjnym czy aplikacji. Innym razem nie zapewnia się filtrowania (konsumujemy wszystkie dane na output z datasource, niezależnie od tego, czy są potrzebne czy nie). Niekiedy integrujemy niepotrzebne źródła danych, a równie często brakuje nam istotnych danych. Brak widoczności lub nieoptymalna widoczność może prowadzić do niezdolności identyfikacji ataku.
Problem nieoptymalnego określenia widoczności bierze się często z braku wiedzy dot. zależności pary – zasoby vs zagrożenia. Aby, rozwiązać ten problem przygotowałem Data Source Framework, który pozwoli Ci zrozumieć wpływ zagrożeń na zasoby i odpowiednio dobrać źródła danych.
Aby to zrobić, wystarczy pięć kroków:
1. Zidentyfikuj warstwy oraz przyporządkuj je do systemów protekcji
2. Wykonaj dekompozycję zasobów
3. Wykonaj modelowanie zagrożeń
4. Stwórz matrycę pokrycia – zidentyfikuj źródła danych dla zagrożeń
5. Przygotuj korelację oraz playbook
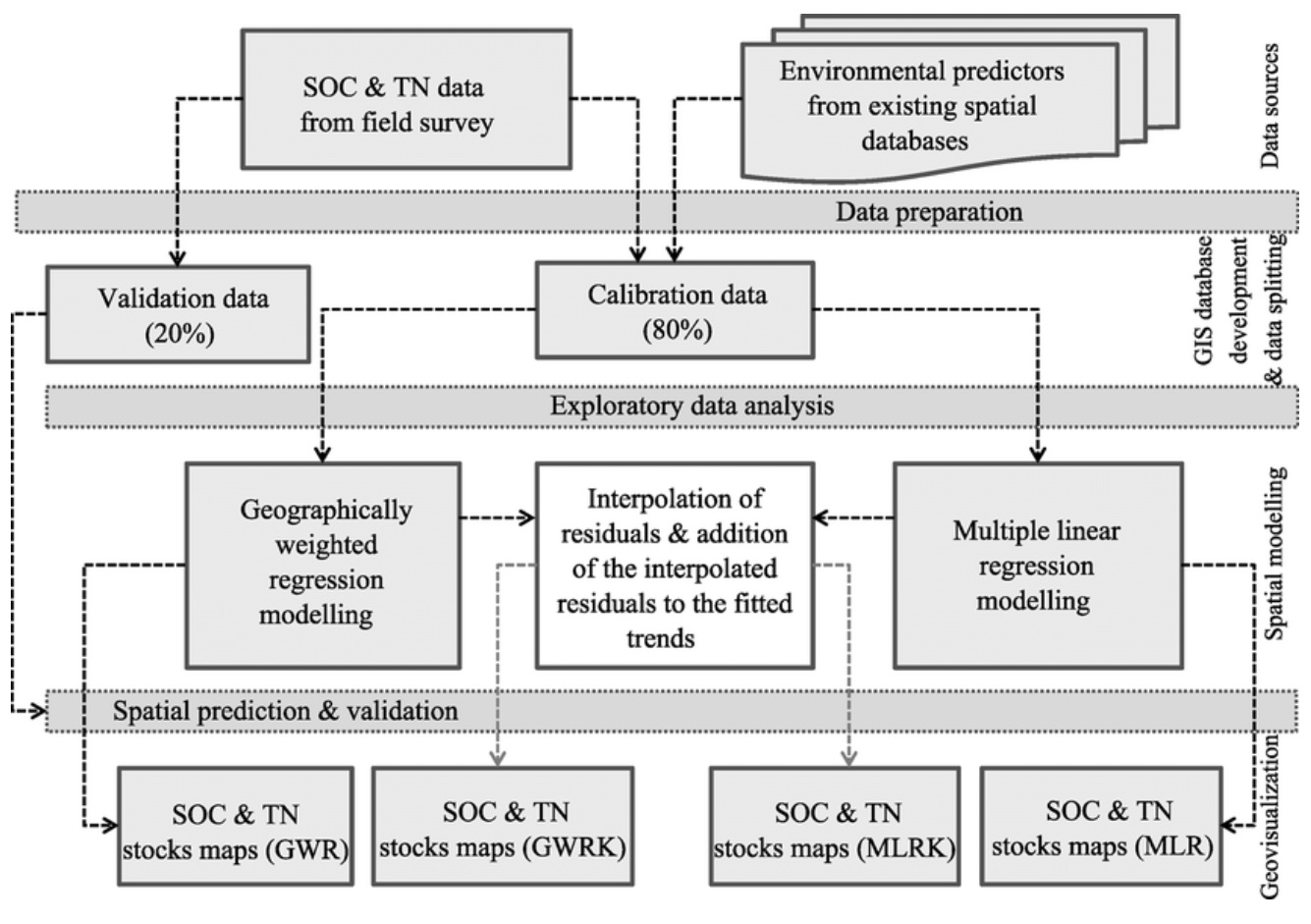
Aby zbudować wiedzę dot. zasobów wykonaj ich pełną dekompozycję (prędzej czy później będzie to wymagane) z podziałem na warstwy (np. fizyczna, sieć, system operacyjny, serwer aplikacyjny, aplikacja). Realizując dekompozycję warto także podnieść temat odpowiedzialności za system (właściciel biznesowy, główny administrator). Następnie zintegrować dane z analizy BIA i analizy ryzyka, które na dalszym etapie pozwolą oceniać poziom incydentu przez proces biznesowy oraz uzyskać widoczność materializacji lub KPI dla ryzyka.
Modelowanie zagrożeń wykorzystaj do określenia, które zagrożenia mogą wystąpić w określonej warstwie zdekomponowanego systemu. W tym celu oprzyj się na odpowiednim modelu MITRE ATT&CK, który agreguje techniki, taktyki i procedury wykorzystywane przez atakujących do osiągnięcia określonych celów.
Matryca pokrycia pozwala na określenie, skąd będziesz wiedział o wystąpieniu danego zagrożenia dla konkretnej warstwy zdekomponowanego systemu. Postaraj się wskazać konkretne źródła danych (np. accesslog apache toccat, windows event log id: 4624), co pozwoli rozważyć filtrowanie danych. Na tym etapie warto również przemyśleć mechanizmy integracji źródła danych (czyli jak daną informacje prześlemy do systemu bezpieczeństwa np. syslog, neftlow, ect.). Ostatnim krokiem będzie wybór najlepszego źródła (w wielu przypadkach będziesz mieć więcej niż jedno źródło danych per zagrożenie).
Posiadając wiedzę dot. konkretnych źródeł danych lokowanych na zasobach, które będą notyfikować określone stany skojarzone z zagrożeniami możesz przejść do budowania logiki reguł monitorowania (np. korelacji w systemie SIEM) trigerujących zdarzenie bezpieczeństwa. Ponadto możesz przygotować konkretne playbooki na wypadek wystąpienia zdarzenia bezpieczeństwa. Oczywiście wiedza ta jest podstawą optymalizacji zbieranych danych, co da Ci możliwość wykorzystania licencji systemów bezpieczeństwa w bardziej optymalny sposób.
Dalej pozostaje już tylko integracja i testy…
Zobacz także
Jak Quirónsalud poprawiło cyberbezpieczeństwo szpitala dzięki Claroty xDome? Sprawdź, jak zabezpieczyć placówkę medyczną!




















































